Wed 25 Jan 2012
This Just In
Posted by anaglyph under Oops!, Words
[9] Comments
So, while we’re on the subject of Ooopsies…
This is how the City of Sydney Events page looked this morning:

This is how it looks now, after Queen Willy wrote to them to say ‘Um…’
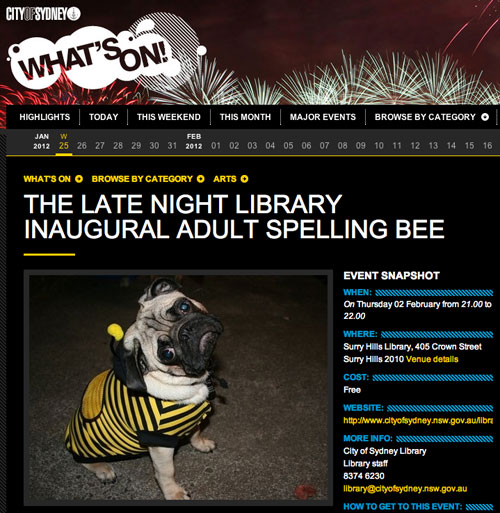
I can’t decide which fills me with the greater delight: the fact that it was actually a mistake (because I just thought they were being clever, to be honest) or the fact that they corrected it (and thus removed all speculation about the magnitude of their cleverness). I suggest that they put ‘inaugural’ on the list for the night, and give a special prize to the person who spells it ‘inagrual’.
After all: What you lose on the swing’s you gain on the roundabout’s.




Thank’s. :-)
Your welcome.
You might appreciate this:
[img]http://imageshack.us/photo/my-images/577/cankn.jpg/[/img]
That didn’t work. Here’s the URL: http://imageshack.us/photo/my-images/577/cankn.jpg/
Can artificial intelligence can replace human brain’s?
I like how they didn’t change the URL address:
http://whatson.cityofsydney.nsw.gov.au/events/12766-the-late-night-library-inagrual-adult-spelling-bee
“Inagrual” – It’s the first hit in Google.
URL is possibly derived from the text in the html. I’m giving them the benefit of the doubt, because if not, then someone at the City of Sydney thinks (or now ‘thought’ – past tense, one hopes) that inaugural was actually spelled like that because they did it twice…
Haha…. that’s hysterical. What a shame queenwilly will be out of town on the night of the spelling bee
That’s one sic (fuly sic) looking Bee too!
The King